
Introduction
La donnée est partout. Elle alimente la stratégie, les opérations, la relation client, la conformité réglementaire… Pourtant, de nombreuses entreprises se retrouvent piégées dès le départ par un mauvais choix d’architecture de stockage : Data Warehouse ou Data Lake ?
Ce dilemme, en apparence purement technique, est en réalité profondément stratégique. Il touche à la façon dont les données sont consommées, gouvernées, partagées et valorisées.
Chez stat4decision, nous accompagnons des structures publiques et privées dans leurs projets data depuis plus de 10 ans. Et ce que nous avons constaté, c’est que le mauvais choix initial d’architecture a un coût considérable : dette technique, doublons, outils inadaptés, rejet des utilisateurs ou blocages opérationnels. Il ne s’agit donc pas seulement de choisir une technologie, mais de définir un cadre de travail pour toute la chaîne de valeur de la donnée.
Cet article s’appuie sur des cas concrets rencontrés en accompagnement, afin de vous permettre de faire un choix éclairé et adapté à vos besoins réels.
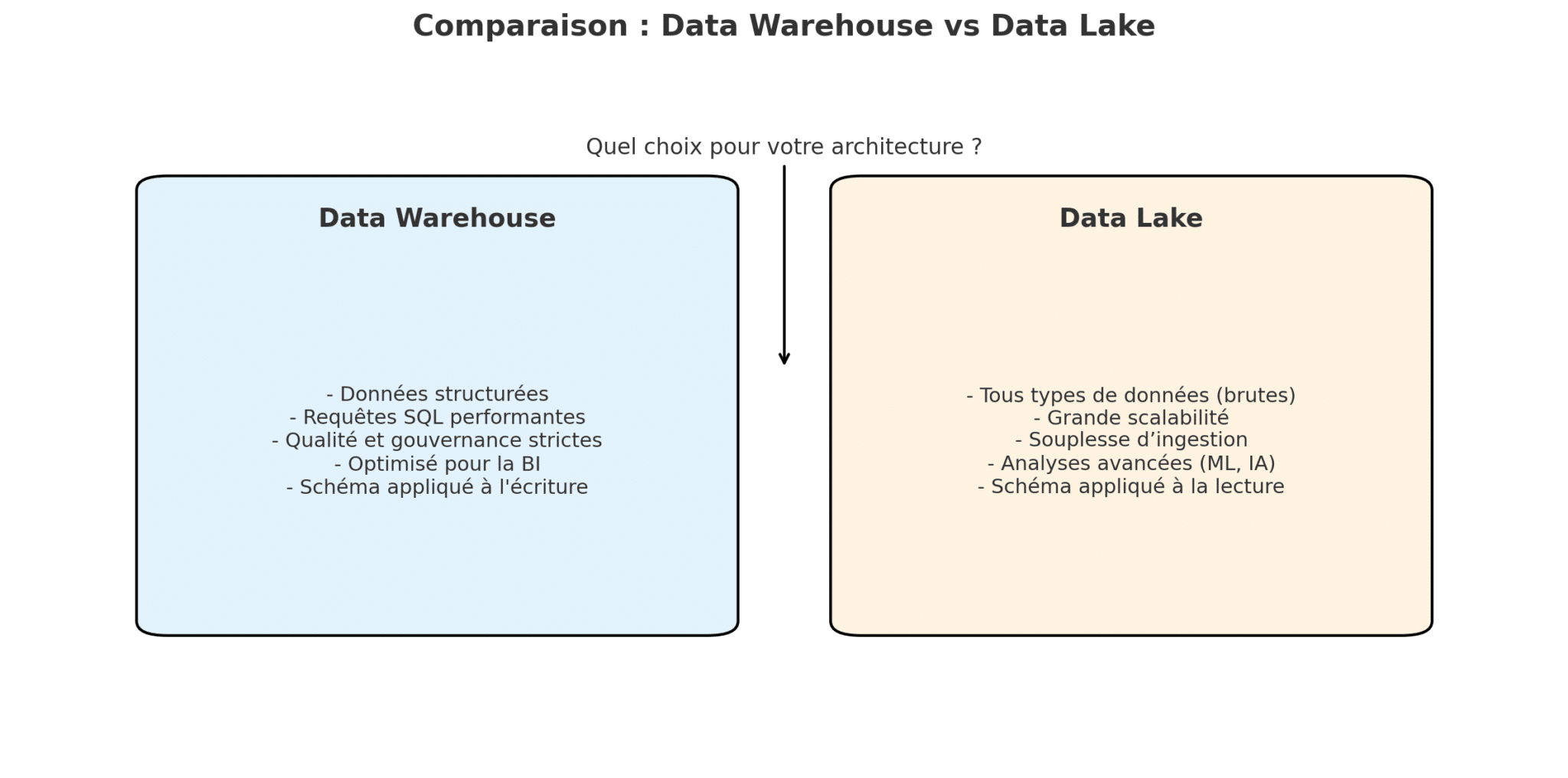
Comprendre les fondamentaux : deux visions de la donnée
Le Data Warehouse, ou entrepôt de données, est pensé pour organiser la donnée comme un produit fini. Il s’agit d’un environnement structuré, modélisé selon des schémas relationnels, où chaque information est contrôlée, gouvernée, prête à être analysée via des requêtes SQL ou des outils de business intelligence. C’est un outil parfaitement adapté à des usages répétitifs, fiables, normalisés : reporting réglementaire, suivi d’indicateurs clés, analyse de performance, tableaux de bord métiers.
Le Data Lake, en revanche, repose sur une vision radicalement différente. Il ne vise pas à produire une donnée « prête à l’emploi », mais à centraliser la donnée brute, dans toute sa diversité : logs de serveurs, fichiers textes, vidéos, données issues de capteurs ou de flux web. Il est conçu pour des équipes qui veulent explorer, tester, construire de nouveaux modèles, entraîner des algorithmes. Il repose sur une logique de conservation massive, avec un schéma appliqué à la lecture, et non à l’écriture.
Il est essentiel de comprendre que ces deux architectures répondent à des besoins différents. C’est justement en confondant ces usages que nombre d’organisations ont commis des erreurs stratégiques.

Des erreurs fréquentes observées sur le terrain
Parmi les erreurs les plus récurrentes, on retrouve le choix d’un Data Lake pour faire du reporting métier classique. Pensant adopter une solution plus moderne et évolutive, certaines entreprises ont misé sur un Data Lake pour centraliser toutes leurs données… mais sans avoir les compétences nécessaires pour les structurer, les modéliser ou les exposer facilement. Résultat : des projets BI enlisés, une incompréhension côté métier, des rapports impossibles à générer sans transformation manuelle préalable. La donnée était bien là, mais inutilisable au quotidien.
À l’inverse, d’autres structures ont choisi un Data Warehouse rigide pour absorber des données issues du web, des réseaux sociaux ou d’objets connectés, pensant pouvoir « forcer » leur structure dans des tables relationnelles. Ce choix a rapidement atteint ses limites. Faute de flexibilité, les données non structurées ont été exclues du périmètre, ou intégrées à grands frais via des développements sur mesure. Cela a freiné l’innovation et empêché les data scientists d’avoir accès à la matière première nécessaire pour expérimenter.
Un autre écueil courant est de penser que le Data Lake est un outil gratuit ou plus économique, car il repose sur du stockage brut. Certes, stocker est peu coûteux. Mais exploiter, transformer et sécuriser les données dans un lac peut rapidement générer des coûts humains et techniques bien plus élevés qu’avec un entrepôt bien conçu. Là encore, des organisations ont été séduites par la promesse du big data sans en mesurer la complexité.
Avant de donner d’orienter un choix, il faut clarifier un certain nombre de points.
Le rôle des connecteurs et moteurs de requêtes
Dans les architectures modernes, le Data Warehouse et le Data Lake ne sont pas seulement des espaces de stockage. Ce sont des composants interconnectés qui s’insèrent dans une architecture de traitement distribuée. C’est pourquoi la question du moteur de requêtes devient cruciale.
Le Data Warehouse s’appuie souvent sur des moteurs hautement optimisés pour les requêtes SQL complexes (comme BigQuery, Snowflake, Amazon Redshift, ou Azure Synapse). Ces solutions cloud gèrent automatiquement la répartition des calculs, la compression des données, le partitionnement, et l’indexation, rendant les analyses BI quasi-instantanées même à très grande échelle.
Côté Data Lake, on s’appuie sur des moteurs comme Presto, Trino, Athena, ou Spark SQL, qui permettent de requêter directement des fichiers sur S3, Azure Data Lake Storage, ou HDFS. Mais contrairement au Data Warehouse, les performances dépendent souvent de l’organisation des fichiers (parquet, ORC, delta…), de leur partitionnement, et de la qualité du schéma implicite. Une mauvaise gestion peut entraîner des surcoûts, voire rendre certaines analyses impossibles.
Ce point est souvent négligé lors de l’implémentation initiale, avec des équipes focalisées sur l’ingestion ou le stockage, au détriment de l’exploitation des données.
Gouvernance, sécurité et gestion des métadonnées : l’angle mort des projets Data Lake
Un autre facteur critique dans le choix entre Data Warehouse et Data Lake réside dans la gouvernance et la maîtrise du cycle de vie de la donnée.
Les entrepôts de données modernes intègrent nativement des outils de catalogue, de contrôle d’accès, de data lineage et de masquage des données sensibles. Cela permet de répondre rapidement à des exigences réglementaires (RGPD, etc.) tout en maintenant la qualité des analyses.
À l’inverse, un Data Lake mal gouverné devient très vite un data swamp, un marécage de données sans documentation ni lisibilité. Pour pallier cela, il est indispensable d’intégrer des outils comme Apache Atlas, DataHub, Collibra, ou Amundsen. Ces plateformes permettent de cataloguer, tracer, versionner, documenter et sécuriser les jeux de données.
Malheureusement, de nombreuses équipes techniques déploient un Data Lake pour répondre à une urgence business ou à une logique d’innovation, sans penser en amont à ces dimensions de qualité et de gestion. Cela conduit souvent à un refactoring complet du système après 1 ou 2 ans.
Vers une convergence des deux mondes : le Lakehouse et les formats transactionnel
Le débat entre Data Lake et Data Warehouse est aujourd’hui bousculé par l’émergence de solutions dites Lakehouse, qui tentent de réunir le meilleur des deux mondes.
Des moteurs comme Databricks, Snowflake, ou Dremio permettent désormais de stocker les données dans des formats ouverts (comme Delta Lake, Apache Iceberg ou Hudi), tout en offrant des capacités transactionnelles, de requêtage SQL performant, de time travel et de versioning.
Ces technologies permettent de gérer les données comme dans un entrepôt, mais avec la flexibilité du stockage brut d’un Data Lake. Cela réduit la duplication des données entre les environnements exploratoires et ceux destinés à la BI, tout en simplifiant la gouvernance.
Les architectures orientées format ouvert + moteur de requêtes universel semblent ainsi s’imposer comme une réponse pragmatique aux limites des architectures traditionnelles.
Orchestration, transformation et exécution : où placer Airflow, dbt, Snowflake et Databricks dans vos choix ?
Quand on parle d’architecture data, le débat ne concerne pas uniquement le choix entre un Data Lake et un Data Warehouse. Il faut également réfléchir aux outils de traitement, de transformation et d’orchestration qui structurent l’ensemble du pipeline. Des plateformes comme Airflow, dbt, Databricks ou Snowflake jouent un rôle fondamental dans ce paysage et doivent être choisis en cohérence avec l’architecture cible.
Airflow : le chef d’orchestre de vos pipelines
Apache Airflow est un orchestrateur de workflows qui s’intègre aussi bien dans des architectures Data Lake que Data Warehouse. Il permet de déclencher, monitorer et gérer l’ensemble des traitements de données, qu’il s’agisse d’une ingestion brute dans un lac ou d’une transformation SQL dans un entrepôt.
Dans une architecture Data Lake, Airflow sera souvent utilisé pour automatiser les stages d’ingestion, de traitement Spark, de formatage en Parquet ou Delta, puis le déplacement vers des zones analytiques.
Dans une architecture Data Warehouse, il peut piloter les exécutions dbt ou les jobs SQL dans un moteur comme Snowflake ou BigQuery.
dbt : le pivot de la transformation analytique
dbt (Data Build Tool) s’inscrit davantage dans une logique de Data Warehouse ou de Lakehouse. Il est utilisé pour structurer, transformer et tester les données avec du SQL versionné. dbt suppose que la donnée est déjà présente dans un entrepôt de type Snowflake, Redshift ou BigQuery, ou dans un lac structuré compatible (comme Delta Lake sur Databricks).
Dans un entrepôt, dbt permet de modulariser les transformations, documenter les modèles, versionner les changements et intégrer des tests de qualité. Il devient le standard de facto pour les équipes analytics cherchant à professionnaliser leur stack.
Dans un Lakehouse, dbt se combine avec Databricks SQL pour orchestrer les transformations sur des tables Delta. Il est de plus en plus utilisé pour réconcilier les mondes data engineering et data analytics.
Snowflake : la puissance de l’entrepôt moderne
Snowflake est un Data Warehouse cloud-native qui a redéfini les standards de performance, d’élasticité et de simplicité. Il séduit les organisations cherchant à exposer des données fiables et gouvernées à l’échelle, tout en offrant des fonctionnalités avancées : time travel, secure data sharing, traitements semi-structurés.
Snowflake n’est pas qu’un entrepôt : il tend vers une logique de Data Cloud intégrant ingestion, partage, transformation (via Snowpark ou dbt) et exécution de modèles. Il devient une brique centrale dans des architectures de type Warehouse-first ou Lakehouse, en complément d’un Data Lake stocké sur S3 ou GCS.
Databricks : de l’ingestion brute au data product
Databricks est historiquement associé au Data Lake, grâce à son moteur Spark et son support natif des fichiers bruts. Mais avec l’arrivée de Delta Lake, puis de Databricks SQL, la plateforme s’est transformée en un véritable moteur de Lakehouse.
Elle permet de collecter, transformer, exposer et requêter les données à tous les stades de leur cycle de vie, dans un même espace. Databricks est aujourd’hui utilisé aussi bien par des data engineers que des data scientists ou des analystes, avec une plateforme unifiée.
La force de Databricks réside dans sa polyvalence : ingestion de fichiers massifs, traitement Spark distribué, exécution de notebooks ML, et requêtage SQL performant sur des tables Delta. Il convient parfaitement aux environnements où les données sont hétérogènes et où la collaboration entre profils techniques est stratégique.
Repenser votre architecture autour des usages… et des outils
Le choix entre Data Lake et Data Warehouse ne doit donc pas être fait en silos, sans penser à l’écosystème d’outils qui vient s’y greffer.
Si vous êtes dans une logique de transformation analytique propre, gouvernée, structurée, une stack orientée Snowflake + dbt + Airflow est un standard efficace et robuste.
Si vos équipes sont davantage tournées vers la data science, les gros volumes, l’exploration de données multi-formats, alors Databricks + Delta Lake + Airflow, ou une plateforme Lakehouse complète, s’impose.
Les entreprises les plus matures construisent des architectures hybrides, où ces outils cohabitent avec des couches bien définies, chacun jouant son rôle dans la chaîne de traitement.
Stat4decision accompagne les organisations dans le choix, la montée en compétences et le déploiement de ces outils à travers des formations spécialisées et des interventions d’architecture et de gouvernance.
Ce que nous recommandons chez stat4decision
Notre conviction, forgée par des dizaines de projets menés auprès d’acteurs publics et de grands groupes privés, est qu’il faut partir des besoins et des pratiques existantes, et non des technologies à la mode. Trop d’équipes ont souffert d’avoir « bricolé » une architecture Data Lake sans gouvernance, ou d’avoir déployé un Data Warehouse trop rigide pour leur réalité.
C’est pourquoi nous proposons non seulement des formations pratiques sur les architectures data modernes (Snowflake, Databricks, BigQuery, dbt…), mais aussi un accompagnement sur mesure pour concevoir votre architecture cible. Nous intervenons en phase d’audit, de choix de solution, d’accompagnement au déploiement, et de montée en compétences des équipes.
Nos formations sont pensées pour des équipes data, techniques et métiers, avec un double objectif : comprendre les enjeux et savoir mettre en œuvre.


Conclusion
Choisir entre Data Lake et Data Warehouse ne doit pas être un choix par défaut ou dicté par l’effet de mode. C’est une décision structurante qui engage les capacités d’analyse, de reporting, de conformité et d’innovation de votre organisation.
Le Data Lake est une solution puissante mais exigeante. Il permet de répondre à des enjeux d’agilité, d’exploration et d’innovation, mais demande à être encadré par une bonne gouvernance, des pratiques de gestion de la qualité et des compétences en architecture data.
Prendre le temps de comprendre les forces et les limites de chaque approche, s’appuyer sur des retours d’expérience concrets, impliquer les parties prenantes, et se faire accompagner si nécessaire : c’est le meilleur moyen de ne pas transformer votre architecture data en échec coûteux.
Et si vous voulez faire les bons choix dès maintenant, nous vous invitons à découvrir notre formation sur les architectures data modernes ou à échanger avec nos équipes pour un diagnostic personnalisé de votre infrastructure.
Contactez-nous ou explorez notre catalogue de formations en ingénierie des données.
Partager cet article