
Dans cet article nous allons appliquer une régression logistique avec python en utilisant deux packages très différents : scikit-learn et statsmodels. Nous verrons les pièges à éviter et le code associé.
La régression logistique porte assez mal son nom car il ne s’agit pas à proprement parler d’une régression au sens classique du terme (on essaye pas d’expliquer une variable quantitative mais de classer des individus dans deux catégories). Cette méthode présente depuis de nombreuses années est la méthode la plus utilisée aujourd’hui en production pour construire des scores. En effet, ses atouts en ont fait une méthode de référence.
Quels sont ses atouts :
- La simplicité du modèle : il s’agit d’un modèle linéaire, la régression logistique est un cas particulier du modèles linéaire généralisé dans lequel on va prédire la probabilité de la réponse 1 plutôt que la valeur directement (0 ou 1).
- La simplicité d’interprétation : le modèle obtenu est un modèle linéaire, c’est-à-dire qu’on obtient des coefficients associés à chaque variable explicative qui permettent de comprendre l’impact de chaque variable sur le choix (entre 0 et 1).
- La disponibilité : cette méthode est disponible dans tous les logiciels classiques de traitement de données (SAS, SPSS…).
- La robustesse du modèle : ce modèle étant très simple, il y a peu de risque de sur-apprentissage et les résultats ont tendance à avoir un bon pouvoir de généralisation.
Tous ces points ont permis à cette méthode de s’imposer comme une référence en classification binaire. Dans le cadre de cet article, nous n’aborderons que le cas binaire, il existe des modèles logistiques pour classer des variables ordinales (modèle logistique ordinal) ou nominales à plus de 2 modalités (modèle logistique multinomial). Ces modèles sont plus rarement utilisés dans la pratique.
Le cas d’usage : le scoring
Dans le cadre d’une campagne de ciblage marketing, on cherche à contacter les clients d’un opérateur téléphonique qui ont l’intention de se désabonner au service. Pour cela, on va essayer de cibler les individus ayant la plus forte probabilité de se désabonner (on a donc une variable binaire sur le fait de se désabonner ou non). Pour mettre en place cet algorithme de scoring des clients, on va donc utiliser un système d’apprentissage en utilisant la base client existante de l’opérateur dans laquelle les anciens clients qui se sont déjà désabonnés ont été conservés.
Afin de scorer de nouveaux clients, on va donc construire un modèle de régression logistique permettant d’expliquer et de prédire le désabonnement. Notre objectif est ici d’extraire les caractéristiques les plus importantes de nos clients.
Les outils en python pour appliquer la régression logistique
Il existe de nombreux packages pour calculer ce type de modèles en python mais les deux principaux sont scikit-learn et statsmodels.
Scikit-learn, le package de machine learning
Scikit-learn est le principal package de machine learning en python, il possède des dizaines de modèles dont la régression logistique. En tant que package de machine learning, il se concentre avant tout sur l’aspect prédictif du modèle de régression logistique, il permettra de prédire très facilement mais sera pauvre sur l’explication et l’interprétation du modèle. Par contre, pour la validation de la qualité prédictive des modèles, l’ajustement des hyper-paramètres et le passage en production de modèles, il est extrêmement efficace.
https://scikit-learn.org/stable/
Statsmodels, le package orienté statistique
Statsmodels est quant à lui beaucoup plus orienté modélisation statistique, il possédera des sorties plus classiques pouvant ressembler aux logiciels de statistiques « classiques ». Par contre, le passage en production des modèles sera beaucoup moins facilité. On sera plus sur de l’explicatif.
https://www.statsmodels.org/stable/index.html
Le code
Nous commençons par récupérer les données et importer les packages :
import pandas as pd
import numpy as np
import statsmodels.api as sm
from sklearn.linear_model import LogisticRegression
data = pd.read_csv("https://www.stat4decision.com/telecom.csv")
data["Churn?"] = data["Churn?"].astype('category')
# on définit x et y
y = data["Churn?"].cat.codes
# on ne prend que les colonnes quantitatives
x = data.select_dtypes(np.number).drop(["Account Length",
"Area Code"],axis=1)On a donc récupéré la cible qui est stockée dans y et les variables explicatives qui sont stockées dans x.
Nous allons pouvoir estimer les paramètres du modèle. Chaque package a ses spécificités et notre objectif est ici d’obtenir des résultats équivalents entre scikit-learn et statmodels.
Le cas scikit-learn
Attention ! Scikit-learn décide par défaut d’appliquer une régularisation sur le modèle. Ceci s’explique par l’objectif prédictif du machine learning mais ceci peut poser des problèmes si votre objectif est de comparer différents outils et leurs résultats (notamment R, SAS…).
On utilisera donc :
modele_logit = LogisticRegression(penalty='none',solver='newton-cg')
modele_logit.fit(x,y)On voit qu’on n’applique pas de pénalité et qu’on prend un solver du type Newton qui est plus classique pour la régression logistique.
Si on veut comprendre les coefficients du modèle, scikit-learn stocke les informations dans .coef_, nous allons les afficher de manière plus agréable dans un DataFrame avec la constante du modèle :
pd.DataFrame(np.concatenate([modele_logit.intercept_.reshape(-1,1),
modele_logit.coef_],axis=1),
index = ["coef"],
columns = ["constante"]+list(x.columns)).TOn obtient donc :
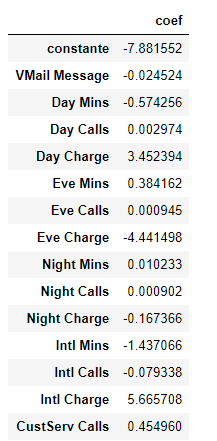
On a bien les coefficients, il faut être prudent sur leur interprétation car comme les données ne sont pas standardisées, leur interprétation dépendra de l’ordre de grandeur des échelles des variables. On voit bien que cette sortie ne nous est pas d’une grande utilitée.
Scikit-learn deviendra intéressant lorsqu’on enchaîne des modèles et qu’on essaye de valider les modèles sur des échantillons de validation. Pour plus de détails sur ces approches, vous trouverez un article ici. Vous pouvez aussi trouver des informations sur cette page GitHub associée à l’ouvrage Python pour le data scientsit.
Le cas statsmodels
Attention ! Statsmodels décide par défaut qu’il n’y a pas de constante, il faut ajouter donc une colonne dans les données pour la constante, on utilise pour cela un outil de statsmodels :
# on ajoute une colonne pour la constante
x_stat = sm.add_constant(x)
# on ajuste le modèle
model = sm.Logit(y, x_stat)
result = model.fit()Une autre source d’erreur vient du fait que la classe Logit attend en premier les variables nommées endogènes (qu’on désire expliquer donc le y) et ensuite les variables exogènes (qui expliquent y donc le x). cette approche est inversée par rapport à scikit-learn.
On obitent ensuite un résumé du modèle beaucoup plus lisible :
result.summary()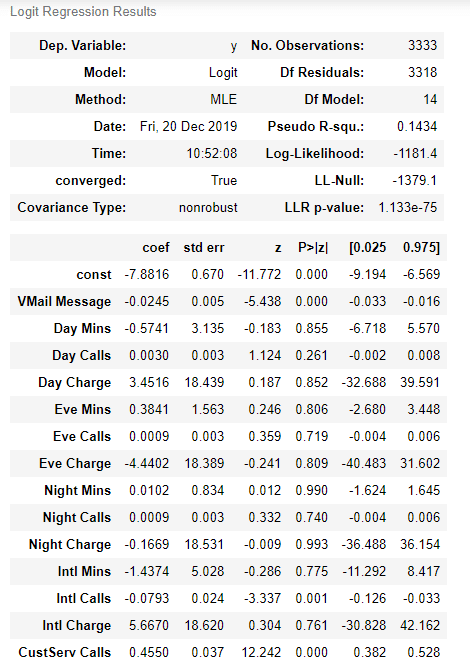
On a dans ce cas tous les détails des résultats d’une régression logistique avec notamment, les coefficients (ce sont les mêmes qu’avec scikit-learn) mais aussi des intervalles de confiance, des p-valeurs et des tests d’hypothèses classiques en statistique.
Conclusions
Cet article n’avait pas pour objectif de montrer la supériorité d’un package sur un autre mais la complémentarité de ces deux packages. En effet, dans un cadre de machine learning et de modèle prédictif, scikit-learn a tous les avantages d’un package extrêmement complet avec une API très uniformisée qui vous permettra d’automatiser et de passer en production vos modèles. En parallèle, statsmodels apparaît comme un bon outil pour la modélisation statistique et l’explication de la régression logistique et il fournira des sorties rassurantes pour les utilisateurs habitués aux logiciels de statistique classique.
Cet article permet aussi de noter une chose : les valeurs par défaut de tous les packages sont souvent différentes et il faut être très attentif à cela pour être capable de comparer des résultats d’un package à un autre.
Pour aller plus loin
Partager cet article