
1. Introduction
La librairie pandas est sans aucun doute la librairie Python de data science la plus utilisée. Un graphique qui circule depuis quelques années – mis à jour ici – et tiré des données de Stack Overflow l’illustre bien. On y observe, qu’en comptabilisant les mentions dans la plate-forme, non seulement la librairie surclasse la stack data de Python, mais qu’elle arrive même au niveau du langage R :
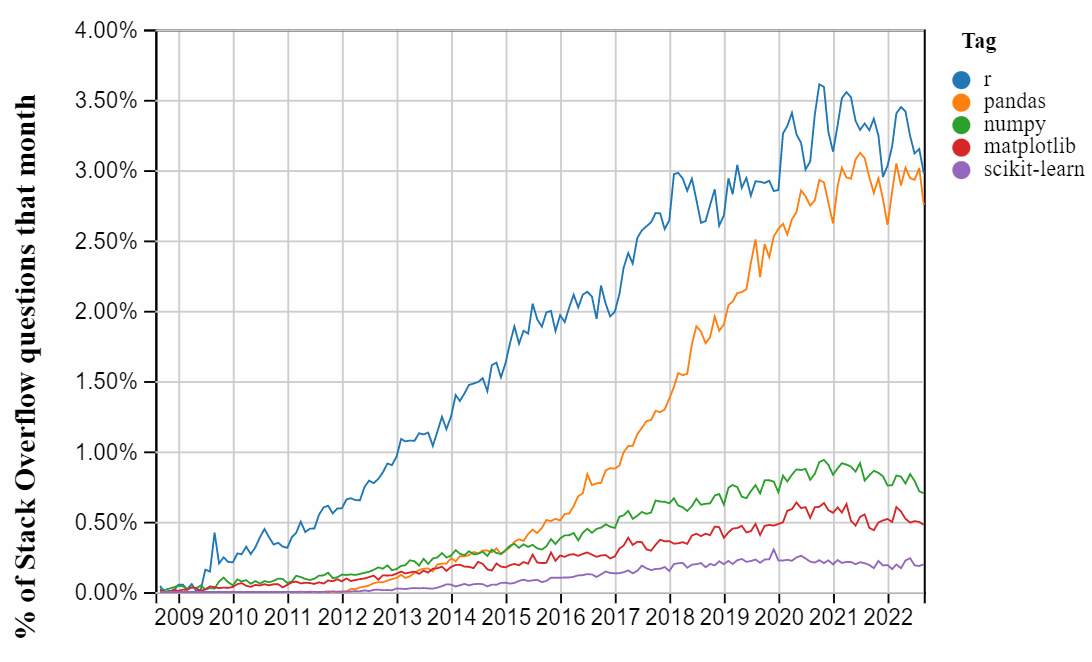
Un article de blog donne également une estimation du nombre d’utilisateurs de la librairie qui était de l’ordre de 5 à 10 millions en 2018.
Pourquoi un tel succès ?
La librairie pandas peut être notamment mise en œuvre pour les différentes tâches définies dans la méthodologie CRISP-DM (CRoss Industry Standard Process for Data Mining, méthodologie développée au début des années 2000 par la société SPSS, elle-même rachetée ensuite par IBM).
Cette méthodologie définit 6 tâches pour les projets data. La librairie pandas est particulièrement adaptée aux tâches essentielles que sont le Data Understanding, la Data Preparation et même le Modeling, directement ou indirectement via d’autres librairies.
La librairie pandas permet effectivement de charger les données à partir d’une grande variété de formats, d’explorer les données en utilisant Jupyter, d’en vérifier la qualité, d’effectuer toutes les opérations relatives à la préparation des données (sélection, nettoyage, feature engineering, intégration, formattage), et enfin, de produire des indicateurs, des graphiques, des modèles statistiques ou de machine learning grâce à sa compatibilité avec tout l’écosystème Python (NumPy, SciPy, Matplotlib, Plotly, statsmodels, scikit-learn, …).
2. La programmation avec pandas
Toutes les opérations listées ci-dessus consistent en général à charger les données sous la forme d’un DataFrame et ensuite à appliquer une série de manipulations, de transformations ou d’opérations sur le DataFrame et sur ses colonnes (Series) avec les méthodes proposées par la librairie pandas.
Avec pandas, il existe plusieurs styles de programmation. Nous allons les présenter rapidement au travers d’un même exemple. Il s’appuie sur le jeu de données des prénoms français fourni par l’Insee (voir https://www.insee.fr/fr/statistiques/2540004?sommaire=4767262). Nous n’utiliserons pas ici toutes les options de la fonction pandas.read_csv() à escient pour illustrer notre propos.
2.1 Utilisation de l’option inplace=True
Dans ce style de programmation, on modifie le DataFrame « sur place » à chaque étape en utilisant l’option inplace=True dans les méthodes utilisées.
Exemple de code :
df = pd.read_csv('data/nat2021_csv.zip', sep=';', na_values="", keep_default_na=False)
# inplace=True
df.rename({'sexe':'gender','preusuel':'name','annais':'year','nombre':'births'}, axis=1,
inplace=True)
df = df.loc[(df['name'] != "_PRENOM_RARES") & (df['year'] != "XXXX")]
df['year'] = df['year'].astype(int)
df['name'] = df['name'].str.title()
df['gender'] = df['gender'].map({1: "M", 2: "F"})
df = df[['year', 'name', 'gender', 'births']]
# inplace=True
df.sort_values(['year', 'gender', 'births', 'name'], ascending=[True, True, False, True],
inplace=True)
# inplace=True
df.reset_index(drop=True, inplace=True)Comme toutes les méthodes de pandas retournent par défaut un nouvel objet, distinct de l’objet initial sur lequel a été appliquée l’opération, l’idée ici est d’éviter la recopie des données en mémoire.
En fait, contrairement à ce qu’elle laisse à penser, l’option inplace=True ne garantit pas l’absence de copie en mémoire. C’est dû à la gestion de la mémoire par le BlockManager associé au DataFrame. Sans entrer dans les détails, un DataFrame est représenté en mémoire par autant de ndarrays de NumPy que de types de données (int, float, datetime, category, object…). Dans certains cas, lorsque par exemple le type des données d’une colonne est modifié, les données sont tout de même recopiées.
The pandas core team discourages the use of the inplace parameter.
2.2 L’affectation de variables
Dans ce style de programmation, on affecte à une variable le résultat de chaque opération, variable qui est utilisée dans l’opération suivante, etc. Les opérations sur les colonnes sont identiques à celles effectuées précédemmment.
Exemple de code :
df = pd.read_csv('data/nat2021_csv.zip',sep=';', na_values="", keep_default_na=False)
df = df.rename({'sexe':'gender','preusuel':'name','annais':'year','nombre':'births'}, axis=1)
df1 = df.loc[(df['name'] != "_PRENOM_RARES") & (df['year'] != "XXXX")]
df1['year'] = df1['year'].astype(int)
df1['name'] = df1['name'].str.title()
df1['gender'] = df1['gender'].map({1: "M", 2: "F"})
df2 = df1[['year', 'name', 'gender', 'births']]
df2 = df2.sort_values(['year', 'gender', 'births', 'name'], ascending=[True, True, False, True])
df2 = df2.reset_index(drop=True)Ce style peut conduire à la création de variables intermédiaires qui seront peu utilisées et qui viendront encombrer tant la mémoire de la machine que celle du data scientist…
2.3 Le method chaining
Dans ce style de programmation, on enchaîne systématiquement les opérations au fur et à mesure sur la Series ou le DataFrame qui résulte de l’opération précédente. L’ensemble des enchaînements est encapsulé entre parenthèses pour des raisons syntaxiques. Aucune variable intermédiaire n’est créée.
Exemple de code :
(pd
.read_csv('data/nat2021_csv.zip',sep=';', na_values="", keep_default_na=False)
.rename(columns={'sexe': 'gender', 'preusuel': 'name', 'annais': 'year', 'nombre': 'births'})
.query('(name != "_PRENOM_RARES") and (year != "XXXX")')
.astype({'year': int})
.assign(name=lambda df_: df_.name.str.title(),
gender=lambda df_: df_.gender.map({1: "M", 2: "F"}))
.loc[:, ['year', 'name', 'gender', 'births']]
.sort_values(['year', 'gender', 'births', 'name'], ascending=[True, True, False, True])
.reset_index(drop=True)
)Dans ce style de programmation, les différentes méthodes invoquées de la Series ou du DataFrame sont alignées verticalement. La lisibilité du programme est améliorée car le data scientist voit immédiatement la nature de chaque opération effectuée. Dans notre petit exemple : chargement des données, renommage des colonnes, sélection des données, conversion d’une colonne, modification de colonnes, modification de l’ordre des colonnes, tri, et enfin, reset de l’index.
The pandas core team now encourages the use of « method chaining ». This is a style of programming in which you chain together multiple method calls into a single statement. This allows you to pass intermediate results from one method to the next rather than storing the intermediate results using variables.
3. Les méthodes fondamentales du method chaining
Dans pandas, il existe des méthodes spéciales qui facilitent ou permettent l’enchaînement des instructions. Ces méthodes reposent essentiellement sur une notation fonctionnelle à base de lambdas.
3.1 Création ou modification de colonnes
La création ou la modification de colonnes d’un DataFrame avec la méthode assign(). Cette méthode prend un nombre quelconque d’arguments à mots-clés et affecte des valeurs aux colonnes correspondant aux mot-clés utilisés.
Par exemple :
- Création ou modification d’une colonne « longueur » en lui attribuant la valeur 0 :
df.assign(longueur=0)- Modification des colonnes « name » et « gender » :
df.assign(name=lambda df_: df_.name.str.title(),
gender=lambda df_: df_.gender.map({1: "M", 2: "F"}))Cette méthode ne modifie pas le DataFrame auquel elle est appliquée. Elle retourne un nouvel objet avec la ou les colonnes ajoutées ou modifiées.
Syntaxiquement, l’utilisation d’une lambda permet de ne pas avoir à désigner explicitement le DataFrame utilisé pour la modification ou l’ajout de colonnes. Il s’agit implicitement de l’objet invoqué et retourné par l’application de la méthode précédente. Dans les exemples donnés, la variable utilisée pour les lambdas est « df_ », mais il est bien sûr possible d’en utiliser une autre.
3.2 Sélection avec des conditions portant sur les valeurs
La sélection dans un DataFrame uniquement avec la méthode query() et une expression logique portant sur les colonnes du DataFrame, ou bien, dans les Series et les DataFrames avec les opérateurs [], loc[] et iloc[] et des sélecteurs sous la forme d’une lambda.
Par exemple :
- Sélection des lignes où l’année de vaut pas « XXXX » :
df.query('year != "XXXX"')ou bien avec une lambda :
df.loc[lambda df_: df_.year != "XXXX"]Là encore, l’utilisation d’une lambda permet de ne pas avoir à désigner explicitement l’objet, Series ou DataFrame, sur lequel est effectuée la sélection.
Remarques pour les DataFrames :
- La notation fonctionnelle reposant sur des lambdas est un peu lourde. Il est effectivement possible de simplifier l’expression des sélections avec la méthode
query(). Les requêtes doivent alors respecter la syntaxe admise par la fonction Pythoneval()dans laquelle les variables désignent les noms des colonnes du DataFrame. - Il est toujours possible d’avoir des noms de colonnes quelconques, mais afin d’alléger le code, les notations poussent un peu à utiliser des noms de colonnes utilisables comme attributs. Exemple :
df.colau lieu dedf['col'].
3.3 Application d’une fonction quelconque
L’application d’une fonction quelconque à des Series ou à des DataFrames peut s’effectuer avec la méthode pipe(func, *args, **kwargs).
Par exemple, la division des valeurs des colonnes d’un DataFrame par leur moyenne respective :
df.pipe(lambda df_: df_.div(df_.mean()))Ici à nouveau, l’utilisation d’une lambda permet de ne pas avoir à désigner explicitement l’objet, Series ou DataFrame, auquel est appliqué la fonction. On verra au paragraphe suivant un exemple d’utilisation de cette méthode sans lambda.
3.4 Les autres méthodes
L’ensemble des méthodes de calcul logique, mathématique ou statistique, de transformation, de combinaison des Series ou des DataFrames et même de production de graphiques peuvent également être utilisées en method chaining puisque d’une manière générale ces méthodes retournent un nouvel objet.
On trouvera ci-dessous un petit exemple complet comprenant la production d’un graphique avec Matplotlib et avec Plotly.
Exemple avec matplotlib.pyplot
Avec l’opérateur plot, il est possible d’invoquer directement les méthodes graphiques de pandas.
import pandas as pd
import matplotlib.pyplot as plt
with plt.style.context('seaborn'):
(pd
.read_csv('data/nat2021_csv.zip',sep=';', na_values="", keep_default_na=False)
.rename(columns={'sexe': 'gender', 'preusuel': 'name', 'annais': 'year', 'nombre': 'births'})
.query('(name != "_PRENOM_RARES") and (year != "XXXX")')
.astype({'year': int})
.assign(name=lambda df_: df_.name.str.title(),
gender=lambda df_: df_.gender.map({1: "M", 2: "F"}))
.loc[:, ['year', 'name', 'gender', 'births']]
.sort_values(['year', 'gender', 'births', 'name'], ascending=[True, True, False, True])
.reset_index(drop=True)
.pivot_table(index="year", columns="gender", values="births", aggfunc="sum")
.plot
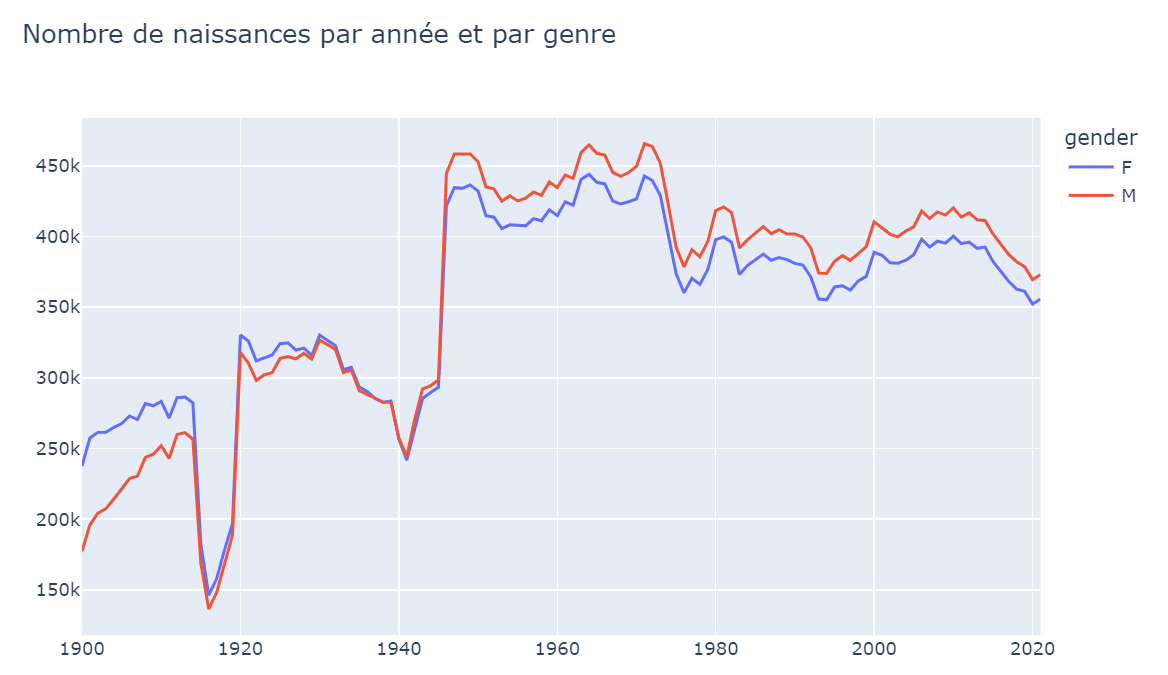
.line(title="Nombre de naissances par année et par genre")
)Exemple avec plotly.express
La librairie plotly.express définit des fonctions graphiques. Il est possible de recourir à la méthode pipe() pour les utiliser en method chaining. Syntaxiquement, l’opération est relativement neutre, on remplace juste l’appel fonctionnel px.line(df, ...) par .pipe(px.line, ...).
import pandas as pd
import plotly.express as px
(pd
.read_csv('data/nat2021_csv.zip',sep=';', na_values="", keep_default_na=False)
.rename(columns={'sexe': 'gender', 'preusuel': 'name', 'annais': 'year', 'nombre': 'births'})
.query('(name != "_PRENOM_RARES") and (year != "XXXX")')
.astype({'year': int})
.assign(name=lambda df_: df_.name.str.title(),
gender=lambda df_: df_.gender.map({1: "M", 2: "F"}))
.loc[:, ['year', 'name', 'gender', 'births']]
.sort_values(['year', 'gender', 'births', 'name'], ascending=[True, True, False, True])
.reset_index(drop=True)
.pivot_table(index="year", columns="gender", values="births", aggfunc="sum")
.pipe(px.line, title="Nombre de naissances par année et par genre", width=800, labels={"value":""})
)
Pour ces librairies graphiques, une fois invoquées dans une séquence de method chaining, le DataFrame ou la Series ne sont plus accessibles : toutes les opérations de manipulation doivent donc être effectuées auparavant.
4. L’intérêt du method chaining
L’usage du method chaining est actuellement considéré comme étant une bonne pratique dans la mise en œuvre de la librairie pandas.
Son intérêt réside sur plusieurs points :
- Comme on l’a vu, l’option
inplace=Truene garantit pas l’absence de copie en mémoire et l’affectation de variables peut conduire à consommer inutilement de la mémoire. - Un des problèmes souvent rencontrés avec pandas est l’alerte
SettingWithCopyWarningqui intervient lorsque l’on cherche à modifier un DataFrame obtenu par une sélection sur un autre DataFrame. En effet, avec pandas, la sélection dans un DataFrame ne produit pas un nouvel objet, mais seulement une vue sur le DataFrame initial. En cas de tentative de modification d’une sélection, donc d’une vue, pandas déclenche cette alerte. Le method chaining, qui s’applique systématiquement sur de nouveaux objets, permet de s’affranchir de ce problème. - La librairie pandas est extrêmement riche et chacun peut coder plus ou moins comme il veut. Le method chaining normalise l’écriture du code. De notre point de vue, on y gagne en lisibilité (même si l’avis n’est pas universellement partagé) et donc en maintenabilité, en permettant à un autre data scientist de modifier plus facilement un script existant. Par ailleurs, l’absence de nommage des variables intermédiaires réduit également la charge mentale du data scientist qui peut se concentrer uniquement sur les opérations effectuées.
- Enfin, le method chaining facilite le débogage du code en permettant au data scientist de commenter facilement les différentes instructions d’une séquence en commençant par la fin. Il peut ainsi accéder facilement aux résultats intermédiaires des calculs. Voir ci-dessous l’exemple précédent avec le graphique commentée, puis le pivot commenté.
Graphique commenté :
(pd
.read_csv('data/nat2021_csv.zip',sep=';', na_values="", keep_default_na=False)
.rename(columns={'sexe': 'gender', 'preusuel': 'name', 'annais': 'year', 'nombre': 'births'})
.query('(name != "_PRENOM_RARES") and (year != "XXXX")')
.astype({'year': int})
.assign(name=lambda df_: df_.name.str.title(),
gender=lambda df_: df_.gender.map({1: "M", 2: "F"}))
.loc[:, ['year', 'name', 'gender', 'births']]
.sort_values(['year', 'gender', 'births', 'name'], ascending=[True, True, False, True])
.reset_index(drop=True)
.pivot_table(index="year", columns="gender", values="births", aggfunc="sum")
# .pipe(px.line, title="Nombre de naissances par année et par genre", width=800, labels={"value":""})
)Pivot et graphique commentés :
(pd
.read_csv('data/nat2021_csv.zip',sep=';', na_values="", keep_default_na=False)
.rename(columns={'sexe': 'gender', 'preusuel': 'name', 'annais': 'year', 'nombre': 'births'})
.query('(name != "_PRENOM_RARES") and (year != "XXXX")')
.astype({'year': int})
.assign(name=lambda df_: df_.name.str.title(),
gender=lambda df_: df_.gender.map({1: "M", 2: "F"}))
.loc[:, ['year', 'name', 'gender', 'births']]
.sort_values(['year', 'gender', 'births', 'name'], ascending=[True, True, False, True])
.reset_index(drop=True)
# .pivot_table(index="year", columns="gender", values="births", aggfunc="sum")
# .pipe(px.line, title="Nombre de naissances par année et par genre", width=800, labels={"value":""})
)5. Pour aller plus loin…
Nous organisons des formations « pandas avancé » qui comprennent le method chaining, la stylisation des DataFrames et bien d’autres caractéristiques de la librairie : https://www.stat4decision.com/fr/formations/formation-pandas-avance/
Nous travaillons également sur un projet de conversion semi-automatique de code pandas en method chaining. Voir la petite vidéo ci-dessous.
N’hésitez pas à nous contacter : https://www.stat4decision.com/fr/contactez-nous/
Références
Sur pandas :
- pandas: powerful Python data analysis toolkit, github, 2022, https://github.com/pandas-dev/pandas
- Marc Garcia, Towards Pandas 1.0, PyData London Meetup #47, August 2018 https://www.youtube.com/watch?v=hK6o_TDXXN8
- Uwe Korn, The one pandas internal I teach all my new colleagues: the BlockManager, 2020 https://uwekorn.com/2020/05/24/the-one-pandas-internal.html
Sur pandas et le method chaining :
- Kevin Markham, What’s the future of the pandas library?, 2018, https://www.dataschool.io/future-of-pandas/
- Adiamaan Keerthi, The Unreasonable Effectiveness of Method Chaining in Pandas, 2019, https://towardsdatascience.com/the-unreasonable-effectiveness-of-method-chaining-in-pandas-15c2109e3c69
- Bindi Chen, Using Pandas Method Chaining to improve code readability – A tutorial for the best practice with Pandas Method Chaining, 2020 https://towardsdatascience.com/using-pandas-method-chaining-to-improve-code-readability-d8517c5626ac
- Matt Harrison, Professional Pandas: The Pandas Assign Method and Chaining, 2022, https://ponder.io/professional-pandas-the-pandas-assign-method-and-chaining/
Partager cet article